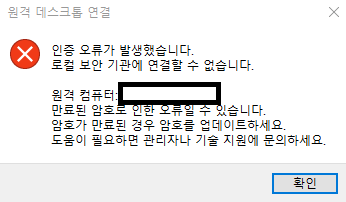
암호도 변경해도 같은 오류가 뜨고
계정 이름 변경으로 PC2로 바꿔서 해보니 계속 오류가 떴음.

다른 방법을 검색해보다가
- 단축키 [Windows+R] 을 눌러 실행 창을 열기
- 실행 창에 control userpasswords2 를 입력 후 엔터

계정이름이 USER여서 안되는거였음..
암호도 변경해도 같은 오류가 뜨고
계정 이름 변경으로 PC2로 바꿔서 해보니 계속 오류가 떴음.
다른 방법을 검색해보다가
계정이름이 USER여서 안되는거였음..
: 당일 벼락치기로 중요해보이는 이론만 보고 갔습니다. (12/30)
1. Json
2. 최소제곱법
3. 박스콕스
4. 차원축소
5. 자기조직화지도 SOM
6. 정규성
7. SVM
8. 드롭아웃
9. 스쿱
10. 0.686 -> f1-score 계산
저는 1,4,7,8번 맞았고 지극히 주관적인 의견이지만 작업형1,2에 올인하고 하루 전에 필답형 기출&예상문제 보고 외우시는 것을 추천합니다.
- 홈페이지에서 응시환경 체험하기를 해보면

이렇게 체험을 할 수 있는데 실제 시험환경과 동일합니다.
파일을 불러오는 a까지 나와있기 때문에 그 이후로 진행하면 됩니다.
1.
1) 1사분위수와 3사분위수 구하기
2) 차이를 절대값으로 표현
3) 소수점 버림
4) 정수형으로 표현 -> 최종 닶은 정수형으로 표현된 값
Q1 = df['컬럼명'].quantile(0.25)
Q3 = df['컬럼명'].quantile(0.75)
sub = np.abs(Q3 - Q1)
i = np.trunc(sub)
a = int(i)답: 36
2. 대충 문제가.. 전체 수(all) 중에서 a와 b가 차지하는 비율을 구하고
그 비율이 0.4~0.5 사이에 존재하고 종류가 video인 개수를 묻는 문제였습니다.
1. ratio가 0.5보다 작고 0.4보다 큰
2. video
답:90
변수명이 기억이 잘 안나서 전체 수 -> all, 종류1-> a, 종류2-> b 로 표현해보자면
# ratio 컬럼을 만듦
df['ratio'] = (df[a] + df[b]) / df['all']
# 비율이 0.4~0.5 사이의 값들
ratio = df[(df['ratio'] > 0.4) & (df['ratio'] < 0.5)]
# 그 중 종류가 비디오인 것의 개수
print(len(ratio['컬럼명'] == 'video'))
3. 2018년 1월에 제작한 영화? 중에서 United Kingdom 단독제작인 영화 개수
- 조건1) 2018년 1월에 제작한 영화
- 조건2) United Kingdom 단독제작 / 컬럼명: country
:Date 컬럼이 September, 6, 2018 이렇게 되어있었습니다.
a['date_added'] = pd.to_datetime(a['date_added'])
a['year'] = a['date_added'].dt.year
a['month'] = a['date_added'].dt.month
cond1 = a['year'] == 2018
cond2 = a['month'] == 1
cond3 = a['country'] == 'United Kingdom'
print(len(a[cond1 & cond2 & cond3]))답: 6
추가로
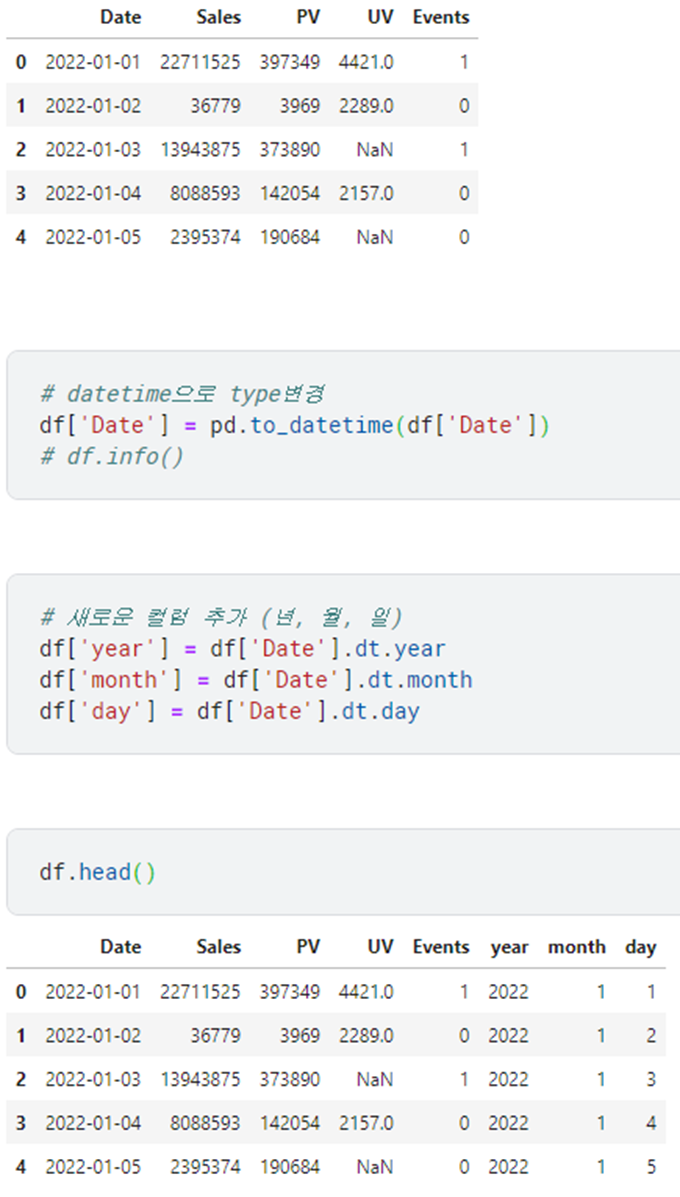
이런 식으로 비슷한 예제로 날짜를 분리하여 조건에 맞는 값을 추출하는 연습을 하면 좋을 것 같습니다.
2. 작업형2
- 사실 제일 막막했는데
[무료] 빅데이터 분석기사 시험 실기(Python) - 인프런 | 강의
국가기술자격증 빅데이터분석기사 실기 with Python 강의입니다. 여러분들의 합격을 응원합니다!, - 강의 소개 | 인프런...
www.inflearn.com
이 분 강의를 듣고 똑같은 유형이 나와서 꾸역꾸역 적었습니다.
무료라서 한번 듣는 것을 추천합니다.
강의 목차 중에서 작업형2 7,8강이 시험문제과 유형이 같았습니다.
(시험에선 결측치가 없었고, 저는 전처리과정은 라벨링, age컬럼만 정규화했습니다..)

응시환경 체험하기처럼 나오는데 이번 시험에서는 y_train이 없었습니다.
X_train의 'segmentation'을 예측하는 문제였습니다.
(X_test에는 segmentation이 없음)
- 전처리: 결측치 없어서 제거안함/ 라벨링/ age만 정규화(나머지 컬럼들은 0 or 1 위주여서..)
- 모델: RandomForestClassifier / AdaBoostClassifier/ VotingClassifier
(모델링은 강의 내용과 동일하게 했습니다.)
시험은 6월 25일에 쳤고
시험결과는 7월 8일에 공개됐습니다.
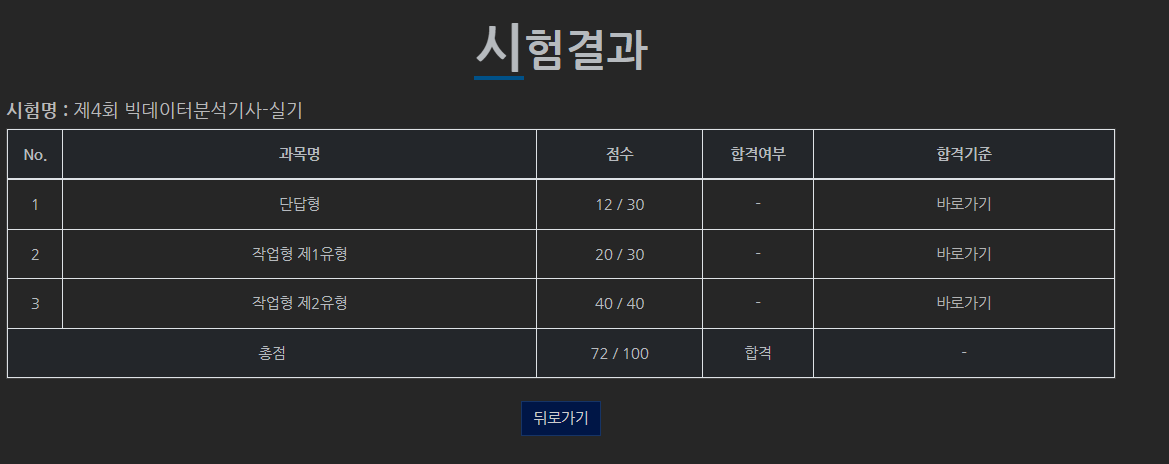
후기 끝.
Releases - OpenCV
Become a Member Stay up to date on OpenCV and Computer Vision news Join our Newsletter
opencv.org














from matplotlib import font_manager, rc
font_path = './file/malgun.ttf' # 글꼴 파일 위치
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
| 판다스 기초) 외부 파일 읽어오기, 원하는 파일형식으로 저장하기 (0) | 2022.05.12 |
|---|---|
| 판다스 기초) 시리즈/데이터프레임, 행/열 이름, 선택,삭제,추가,변경,초기화,산술연산 (0) | 2022.05.09 |
import pandas as pd
file_path = './file/read_csv_sample.csv'
df1 = pd.read_csv(file_path)
print(df1)
c0 c1 c2 c3
0 5 1 4 7
1 6 2 5 8
2 7 3 6 9
df2 = pd.read_csv(file_path, header=None)
print(df2)
0 1 2 3
0 c0 c1 c2 c3
1 5 1 4 7
2 6 2 5 8
3 7 3 6 9
df3 = pd.read_csv(file_path, index_col=None)
print(df3)
c0 c1 c2 c3
0 5 1 4 7
1 6 2 5 8
2 7 3 6 9
df4 = pd.read_csv(file_path, index_col='c0')
print(df4)
c1 c2 c3
c0
5 1 4 7
6 2 5 8
7 3 6 9
df5 = pd.read_csv(file_path, header=1)
print(df5)
5 1 4 7
0 6 2 5 8
1 7 3 6 9
df6 = pd.read_csv(file_path, index_col=3)
print(df6)
c0 c1 c2
c3
7 5 1 4
8 6 2 5
9 7 3 6
pip install xlrd
Collecting xlrd
Using cached xlrd-2.0.1-py2.py3-none-any.whl (96 kB)
Installing collected packages: xlrd
Successfully installed xlrd-2.0.1
Note: you may need to restart the kernel to use updated packages.
pip install openpyxl
Collecting openpyxl
Using cached openpyxl-3.0.9-py2.py3-none-any.whl (242 kB)
Collecting et-xmlfile
Using cached et_xmlfile-1.1.0-py3-none-any.whl (4.7 kB)
Installing collected packages: et-xmlfile, openpyxl
Successfully installed et-xmlfile-1.1.0 openpyxl-3.0.9
Note: you may need to restart the kernel to use updated packages.
df1 = pd.read_excel('./file/남북한발전전력량.xlsx')
print(df1)
전력량 (억㎾h) 발전 전력별 1990 1991 1992 1993 1994 1995 1996 1997 ... 2007 \
0 남한 합계 1077 1186 1310 1444 1650 1847 2055 2244 ... 4031
1 NaN 수력 64 51 49 60 41 55 52 54 ... 50
2 NaN 화력 484 573 696 803 1022 1122 1264 1420 ... 2551
3 NaN 원자력 529 563 565 581 587 670 739 771 ... 1429
4 NaN 신재생 - - - - - - - - ... -
5 북한 합계 277 263 247 221 231 230 213 193 ... 236
6 NaN 수력 156 150 142 133 138 142 125 107 ... 133
7 NaN 화력 121 113 105 88 93 88 88 86 ... 103
8 NaN 원자력 - - - - - - - - ... -
2008 2009 2010 2011 2012 2013 2014 2015 2016
0 4224 4336 4747 4969 5096 5171 5220 5281 5404
1 56 56 65 78 77 84 78 58 66
2 2658 2802 3196 3343 3430 3581 3427 3402 3523
3 1510 1478 1486 1547 1503 1388 1564 1648 1620
4 - - - - 86 118 151 173 195
5 255 235 237 211 215 221 216 190 239
6 141 125 134 132 135 139 130 100 128
7 114 110 103 79 80 82 86 90 111
8 - - - - - - - - -
[9 rows x 29 columns]
df2 = pd.read_excel('./file/남북한발전전력량.xlsx', engine='openpyxl')
print(df2)
전력량 (억㎾h) 발전 전력별 1990 1991 1992 1993 1994 1995 1996 1997 ... 2007 \
0 남한 합계 1077 1186 1310 1444 1650 1847 2055 2244 ... 4031
1 NaN 수력 64 51 49 60 41 55 52 54 ... 50
2 NaN 화력 484 573 696 803 1022 1122 1264 1420 ... 2551
3 NaN 원자력 529 563 565 581 587 670 739 771 ... 1429
4 NaN 신재생 - - - - - - - - ... -
5 북한 합계 277 263 247 221 231 230 213 193 ... 236
6 NaN 수력 156 150 142 133 138 142 125 107 ... 133
7 NaN 화력 121 113 105 88 93 88 88 86 ... 103
8 NaN 원자력 - - - - - - - - ... -
2008 2009 2010 2011 2012 2013 2014 2015 2016
0 4224 4336 4747 4969 5096 5171 5220 5281 5404
1 56 56 65 78 77 84 78 58 66
2 2658 2802 3196 3343 3430 3581 3427 3402 3523
3 1510 1478 1486 1547 1503 1388 1564 1648 1620
4 - - - - 86 118 151 173 195
5 255 235 237 211 215 221 216 190 239
6 141 125 134 132 135 139 130 100 128
7 114 110 103 79 80 82 86 90 111
8 - - - - - - - - -
[9 rows x 29 columns]
df = pd.read_json('./file/read_json_sample.json')
print(df)
name year developer opensource
pandas 2008 Wes Mckinneye True
NumPy 2006 Travis Oliphant True
matplotlib 2003 John D. Hunter True
print(df.index)
Index(['pandas', 'NumPy', 'matplotlib'], dtype='object')
pip install lxml
Requirement already satisfied: lxml in c:\users\for\miniconda3\lib\site-packages (4.8.0)
Note: you may need to restart the kernel to use updated packages.
url = './file/sample.html'
tables = pd.read_html(url)
print(len(tables)) # table 수 확인
print('\n')
for i in range(len(tables)):
print(f'tables[{i}]')
print(tables[i])
print('\n')
2
tables[0]
Unnamed: 0 c0 c1 c2 c3
0 0 0 1 4 7
1 1 1 2 5 8
2 2 2 3 6 9
tables[1]
name year developer opensource
0 NumPy 2006 Travis Oliphant True
1 matplotlib 2003 John D. Hunter True
2 pandas 2008 Wes Mckinneye True
df = tables[1]
df.set_index(['name'], inplace=True)
print(df)
year developer opensource
name
NumPy 2006 Travis Oliphant True
matplotlib 2003 John D. Hunter True
pandas 2008 Wes Mckinneye True
data = {'name' : ['Jenny', 'Riah', 'Paul'],
'algol': ["A", "A+", "B"],
'basic': ["C", "B", "B+"],
'c++' : ['B+', 'C+', 'C']
}
df = pd.DataFrame(data)
df.set_index('name', inplace=True) #name 열을 인덱스로 지정
print(df)
algol basic c++
name
Jenny A C B+
Riah A+ B C+
Paul B B+ C
df.to_csv('./file/df_sample_jh.csv') # csv 파일로 저장
df.to_json('./file/df_sample_jh.json') # json 파일로 저장
df.to_excel('./file/df_sample_jh.xlsx') # excel 파일로 저장
data1 = {'name' : ['Jenny', 'Riah', 'Paul'],
'algol': ["A", "A+", "B"],
'basic': ["C", "B", "B+"],
'c++' : ['B+', 'C+', 'C']
}
data2 = {'c0' : [1,2,3],
'c1' : [4,5,6],
'c2' : [7,8,9],
'c3' : [10,11,12],
'c4' : [13,14,15]
}
df1 = pd.DataFrame(data1)
df1.set_index('name', inplace=True)
print(df1)
algol basic c++
name
Jenny A C B+
Riah A+ B C+
Paul B B+ C
df2 = pd.DataFrame(data2)
df2.set_index('c0', inplace=True)
print(df2)
c1 c2 c3 c4
c0
1 4 7 10 13
2 5 8 11 14
3 6 9 12 15
#df1을 sheet1으로, df2를 sheet2로 저장
writer = pd.ExcelWriter('./file/excelwriter_jh.xlsx')
df1.to_excel(writer, sheet_name='select1')
df2.to_excel(writer, sheet_name='select2')
writer.save()
| 파이썬, matplotlib 한글 깨짐 해결 (0) | 2022.05.23 |
|---|---|
| 판다스 기초) 시리즈/데이터프레임, 행/열 이름, 선택,삭제,추가,변경,초기화,산술연산 (0) | 2022.05.09 |
import pandas as pd
import numpy as np
df = pd.DataFrame([[15, '남', '덕영중'], [17, '여', '수리중']], index = ['준서', '예은'], columns = ['나이', '성별', '학교'])
print(df)
나이 성별 학교 준서 15 남 덕영중 예은 17 여 수리중
df.index = ['학생1', '학생2']
df.columns = ['연령', '남녀', '소속']
print(df)
연령 남녀 소속 학생1 15 남 덕영중 학생2 17 여 수리중
# 나이-> 연령, 성별-> 남녀, '학교'-> 소속
# 준서-> 학생1, 예은-> 학생2
df.rename(columns={'나이':'연령', '성별':'남녀', '학교':'소속'}, inplace=True)
df.rename(index={'준서':'학생1', '예은': '학생2'}, inplace=True)
print(df)
연령 남녀 소속 학생1 15 남 덕영중 학생2 17 여 수리중
exam_data = {'수학': [90, 80, 70], '영어': [98, 89, 95], '음악': [85, 95, 100], '체육': [100, 90, 90]}
df = pd.DataFrame(exam_data, index = ['서준', '우현', '인아'])
print(df)
수학 영어 음악 체육 서준 90 98 85 100 우현 80 89 95 90 인아 70 95 100 90
df2 = df[:]
df2.drop('우현', inplace=True)
print(df2)
수학 영어 음악 체육 서준 90 98 85 100 인아 70 95 100 90
C:\Users\for\AppData\Local\Temp\ipykernel_24256\2087369725.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df2.drop('우현', inplace=True)
df3 = df[:]
df3.drop(['우현', '인아'], inplace=True)
print(df3)
수학 영어 음악 체육 서준 90 98 85 100
C:\Users\for\AppData\Local\Temp\ipykernel_24256\864553166.py:2: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy df3.drop(['우현', '인아'], inplace=True)
df4 = df.copy()
df4.drop('수학', axis=1, inplace=True)
print(df4)
영어 음악 체육 서준 98 85 100 우현 89 95 90 인아 95 100 90
df5 = df.copy()
df5.drop(['영어', '음악'], axis = 1, inplace=True)
print(df5)
수학 체육 서준 90 100 우현 80 90 인아 70 90
label1 = df.loc['서준']
print(label1, '\n')
position1 = df.iloc[0]
print(position1)
수학 90 영어 98 음악 85 체육 100 Name: 서준, dtype: int64 수학 90 영어 98 음악 85 체육 100 Name: 서준, dtype: int64
label2 = df.loc[['서준', '우현']]
position2 = df.iloc[[0,1]]
print(label2, '\n', position2)
수학 영어 음악 체육
서준 90 98 85 100
우현 80 89 95 90
수학 영어 음악 체육
서준 90 98 85 100
우현 80 89 95 90
label3 = df.loc['서준':'우현']
position3 = df.iloc[0:1]
print(label3, ' \n', position3)
수학 영어 음악 체육
서준 90 98 85 100
우현 80 89 95 90
수학 영어 음악 체육
서준 90 98 85 100
exam_data = {'이름' : ['서준', '우현', '인아'], '수학': [90, 80, 70], '영어': [98, 89, 95], '음악': [85, 95, 100], '체육': [100, 90, 90]}
df = pd.DataFrame(exam_data)
print(df)
print(type(df))
이름 수학 영어 음악 체육 0 서준 90 98 85 100 1 우현 80 89 95 90 2 인아 70 95 100 90 <class 'pandas.core.frame.DataFrame'>
math1 = df['수학']
print(math1)
print(type(math1))
0 90 1 80 2 70 Name: 수학, dtype: int64 <class 'pandas.core.series.Series'>
english = df.영어
print(english)
print(type(english))
0 98 1 89 2 95 Name: 영어, dtype: int64 <class 'pandas.core.series.Series'>
music_gym = df[['음악', '체육']]
print(music_gym)
print(type(music_gym))
음악 체육 0 85 100 1 95 90 2 100 90 <class 'pandas.core.frame.DataFrame'>
math2 = df[['수학']]
print(math2)
print(type(math2))
수학 0 90 1 80 2 70 <class 'pandas.core.frame.DataFrame'>
exam_data = {'이름' : ['서준', '우현', '인아'], '수학': [90, 80, 70], '영어': [98, 89, 95], '음악': [85, 95, 100], '체육': [100, 90, 90]}
df = pd.DataFrame(exam_data)
df.set_index('이름', inplace=True)
print(df)
수학 영어 음악 체육 이름 서준 90 98 85 100 우현 80 89 95 90 인아 70 95 100 90
a = df.loc['서준', '음악']
print(a)
b = df.iloc[0, 2]
print(b)
85 85
c = df.loc['서준', ['음악', '체육']]
print(c)
음악 85 체육 100 Name: 서준, dtype: int64
d = df.iloc[0, [2,3]]
print(d)
음악 85 체육 100 Name: 서준, dtype: int64
e = df.loc['서준', '음악': '체육']
print(e)
음악 85 체육 100 Name: 서준, dtype: int64
f = df.iloc[0, 2:]
print(f)
음악 85 체육 100 Name: 서준, dtype: int64
exam_data = {'이름' : ['서준', '우현', '인아'], '수학': [90, 80, 70], '영어': [98, 89, 95], '음악': [85, 95, 100], '체육': [100, 90, 90]}
df = pd.DataFrame(exam_data)
df['국어'] = 80
print(df)
이름 수학 영어 음악 체육 국어 0 서준 90 98 85 100 80 1 우현 80 89 95 90 80 2 인아 70 95 100 90 80
exam_data = {'이름' : ['서준', '우현', '인아'], '수학': [90, 80, 70], '영어': [98, 89, 95], '음악': [85, 95, 100], '체육': [100, 90, 90]}
df = pd.DataFrame(exam_data)
print(df)
이름 수학 영어 음악 체육 0 서준 90 98 85 100 1 우현 80 89 95 90 2 인아 70 95 100 90
df.loc[3] = 0
print(df)
이름 수학 영어 음악 체육 0 서준 90 98 85 100 1 우현 80 89 95 90 2 인아 70 95 100 90 3 0 0 0 0 0
df.loc[4] = ['동규', 90, 80, 70, 60]
print(df)
이름 수학 영어 음악 체육 0 서준 90 98 85 100 1 우현 80 89 95 90 2 인아 70 95 100 90 3 0 0 0 0 0 4 동규 90 80 70 60
# 기존 행 복사
df.loc['행5'] = df.loc[3]
print(df)
이름 수학 영어 음악 체육 0 서준 90 98 85 100 1 우현 80 89 95 90 2 인아 70 95 100 90 3 0 0 0 0 0 4 동규 90 80 70 60 행5 0 0 0 0 0
exam_data = {'이름' : ['서준', '우현', '인아'], '수학': [90, 80, 70], '영어': [98, 89, 95], '음악': [85, 95, 100], '체육': [100, 90, 90]}
df = pd.DataFrame(exam_data)
print(df)
이름 수학 영어 음악 체육 0 서준 90 98 85 100 1 우현 80 89 95 90 2 인아 70 95 100 90
# 이름 열을 새로운 인덱스로 지정
df.set_index('이름', inplace=True)
print(df)
수학 영어 음악 체육 이름 서준 90 98 85 100 우현 80 89 95 90 인아 70 95 100 90
df.iloc[0][3] = 80
print(df)
수학 영어 음악 체육 이름 서준 90 98 85 80 우현 80 89 95 90 인아 70 95 100 90
df.loc['서준']['체육'] = 90
print(df)
수학 영어 음악 체육 이름 서준 90 98 85 90 우현 80 89 95 90 인아 70 95 100 90
df.loc['서준', '체육'] = 100
print(df)
수학 영어 음악 체육 이름 서준 90 98 85 100 우현 80 89 95 90 인아 70 95 100 90
df.loc['서준', ['음악', '체육']] = 50
print(df)
수학 영어 음악 체육 이름 서준 90 98 50 50 우현 80 89 95 90 인아 70 95 100 90
df.loc['서준', ['음악', '체육']] = 100, 50
print(df)
수학 영어 음악 체육 이름 서준 90 98 100 50 우현 80 89 95 90 인아 70 95 100 90
exam_data = {'이름' : ['서준', '우현', '인아'], '수학': [90, 80, 70], '영어': [98, 89, 95], '음악': [85, 95, 100], '체육': [100, 90, 90]}
df = pd.DataFrame(exam_data)
print(df)
이름 수학 영어 음악 체육 0 서준 90 98 85 100 1 우현 80 89 95 90 2 인아 70 95 100 90
df = df.transpose()
print(df)
0 1 2 이름 서준 우현 인아 수학 90 80 70 영어 98 89 95 음악 85 95 100 체육 100 90 90
#한번 더 바꾸면 원본 데이터프레임
df = df.T
print(df)
이름 수학 영어 음악 체육 0 서준 90 98 85 100 1 우현 80 89 95 90 2 인아 70 95 100 90
exam_data = {'이름' : ['서준', '우현', '인아'], '수학': [90, 80, 70], '영어': [98, 89, 95], '음악': [85, 95, 100], '체육': [100, 90, 90]}
df = pd.DataFrame(exam_data)
print(df)
이름 수학 영어 음악 체육 0 서준 90 98 85 100 1 우현 80 89 95 90 2 인아 70 95 100 90
ndf = df.set_index(['이름'])
print(ndf)
수학 영어 음악 체육 이름 서준 90 98 85 100 우현 80 89 95 90 인아 70 95 100 90
ndf2 = ndf.set_index('음악')
print(ndf2)
수학 영어 체육 음악 85 90 98 100 95 80 89 90 100 70 95 90
ndf3 = ndf.set_index(['수학', '음악'])
print(ndf3)
영어 체육 수학 음악 90 85 98 100 80 95 89 90 70 100 95 90
dict_data = {'c0' : [1,2,3], 'c1': [4,5,6], 'c2': [7,8,9], 'c3': [10,11,12], 'c4':[13,14,15]}
df = pd.DataFrame(dict_data, index=['r0', 'r1', 'r2'])
print(df)
c0 c1 c2 c3 c4 r0 1 4 7 10 13 r1 2 5 8 11 14 r2 3 6 9 12 15
new_index = ['r0', 'r1', 'r2', 'r3', 'r4']
ndf = df.reindex(new_index)
print(ndf)
# NaN = "Not a Number", 누락데이터
c0 c1 c2 c3 c4 r0 1.0 4.0 7.0 10.0 13.0 r1 2.0 5.0 8.0 11.0 14.0 r2 3.0 6.0 9.0 12.0 15.0 r3 NaN NaN NaN NaN NaN r4 NaN NaN NaN NaN NaN
ndf2 = df.reindex(new_index, fill_value = 0)
print(ndf2)
c0 c1 c2 c3 c4 r0 1 4 7 10 13 r1 2 5 8 11 14 r2 3 6 9 12 15 r3 0 0 0 0 0 r4 0 0 0 0 0
dict_data = {'c0' : [1,2,3], 'c1': [4,5,6], 'c2': [7,8,9], 'c3': [10,11,12], 'c4':[13,14,15]}
df = pd.DataFrame(dict_data, index=['r0', 'r1', 'r2'])
print(df)
c0 c1 c2 c3 c4 r0 1 4 7 10 13 r1 2 5 8 11 14 r2 3 6 9 12 15
ndf = df.reset_index()
print(ndf)
index c0 c1 c2 c3 c4 0 r0 1 4 7 10 13 1 r1 2 5 8 11 14 2 r2 3 6 9 12 15
dict_data = {'c0' : [1,2,3], 'c1': [4,5,6], 'c2': [7,8,9], 'c3': [10,11,12], 'c4':[13,14,15]}
df = pd.DataFrame(dict_data, index=['r0', 'r1', 'r2'])
print(df)
c0 c1 c2 c3 c4 r0 1 4 7 10 13 r1 2 5 8 11 14 r2 3 6 9 12 15
ndf = df.sort_index(ascending=False)
print(ndf)
c0 c1 c2 c3 c4 r2 3 6 9 12 15 r1 2 5 8 11 14 r0 1 4 7 10 13
# c1 열을 기준으로 데이터프레임을 내림차순 정렬
ndf = df.sort_values(by='c1', ascending=False)
print(ndf)
c0 c1 c2 c3 c4 r2 3 6 9 12 15 r1 2 5 8 11 14 r0 1 4 7 10 13
student1 = pd.Series({'국어':100, '영어':80, '수학':90})
print(student1)
국어 100 영어 80 수학 90 dtype: int64
# student1의 과목별 점수를 100으로 나눔
percentage = student1/100
print(percentage)
print(type(percentage))
국어 1.0 영어 0.8 수학 0.9 dtype: float64 <class 'pandas.core.series.Series'>
student1 = pd.Series({'국어':100, '영어':80, '수학':90})
student2 = pd.Series({'수학':80, '국어':90, '영어':80})
print(student1)
print('\n')
print(student2)
국어 100 영어 80 수학 90 dtype: int64 수학 80 국어 90 영어 80 dtype: int64
addition = student1 + student2 # 덧셈
subtraction = student1 - student2 # 뺄셈
multiplication = student1 * student2 # 곱셈
division = student1 / student2 # 나눗셈
print(type(division))
<class 'pandas.core.series.Series'>
result = pd.DataFrame([addition, subtraction, multiplication, division], index=['덧셈', '뺄셈','곱셈', '나눗셈'])
print(result)
국어 수학 영어 덧셈 190.000000 170.000 160.0 뺄셈 10.000000 10.000 0.0 곱셈 9000.000000 7200.000 6400.0 나눗셈 1.111111 1.125 1.0
student1 = pd.Series({'국어':np.nan, '영어':80, '수학':90})
student2 = pd.Series({'수학':80, '국어':90})
print(student1)
print('\n')
print(student2)
국어 NaN 영어 80.0 수학 90.0 dtype: float64 수학 80 국어 90 dtype: int64
addition = student1 + student2 # 덧셈
subtraction = student1 - student2 # 뺄셈
multiplication = student1 * student2 # 곱셈
division = student1 / student2 # 나눗셈
print(type(division))
<class 'pandas.core.series.Series'>
result = pd.DataFrame([addition, subtraction, multiplication, division], index=['덧셈', '뺄셈','곱셈', '나눗셈'])
print(result)
국어 수학 영어 덧셈 NaN 170.000 NaN 뺄셈 NaN 10.000 NaN 곱셈 NaN 7200.000 NaN 나눗셈 NaN 1.125 NaN
student1 = pd.Series({'국어':np.nan, '영어':80, '수학':90})
student2 = pd.Series({'수학':80, '국어':90})
print(student1)
print('\n')
print(student2)
국어 NaN 영어 80.0 수학 90.0 dtype: float64 수학 80 국어 90 dtype: int64
sr_add = student1.add(student2, fill_value=0) # 덧셈
sr_sub = student1.sub(student2, fill_value=0) # 뺄셈
sr_mul = student1.mul(student2, fill_value=0) # 곱셈
sr_div = student1.div(student2, fill_value=0) # 나눗셈
result = pd.DataFrame([sr_add, sr_sub, sr_mul, sr_div], index=['덧셈', '뺄셈','곱셈', '나눗셈'])
print(result)
# inf -> 80을 0으로 나누어서 무한대
국어 수학 영어 덧셈 90.0 170.000 80.0 뺄셈 -90.0 10.000 80.0 곱셈 0.0 7200.000 0.0 나눗셈 0.0 1.125 inf
pip install seaborn
Collecting seaborn Downloading seaborn-0.11.2-py3-none-any.whl (292 kB) Requirement already satisfied: matplotlib>=2.2 in c:\users\for\miniconda3\lib\site-packages (from seaborn) (3.5.1) Requirement already satisfied: numpy>=1.15 in c:\users\for\miniconda3\lib\site-packages (from seaborn) (1.19.5) Collecting scipy>=1.0 Downloading scipy-1.8.0-cp39-cp39-win_amd64.whl (36.9 MB) Requirement already satisfied: pandas>=0.23 in c:\users\for\miniconda3\lib\site-packages (from seaborn) (1.4.2) Requirement already satisfied: pillow>=6.2.0 in c:\users\for\miniconda3\lib\site-packages (from matplotlib>=2.2->seaborn) (9.1.0) Requirement already satisfied: kiwisolver>=1.0.1 in c:\users\for\miniconda3\lib\site-packages (from matplotlib>=2.2->seaborn) (1.4.2) Requirement already satisfied: fonttools>=4.22.0 in c:\users\for\miniconda3\lib\site-packages (from matplotlib>=2.2->seaborn) (4.33.3) Requirement already satisfied: pyparsing>=2.2.1 in c:\users\for\miniconda3\lib\site-packages (from matplotlib>=2.2->seaborn) (3.0.4) Requirement already satisfied: cycler>=0.10 in c:\users\for\miniconda3\lib\site-packages (from matplotlib>=2.2->seaborn) (0.11.0) Requirement already satisfied: python-dateutil>=2.7 in c:\users\for\miniconda3\lib\site-packages (from matplotlib>=2.2->seaborn) (2.8.2) Requirement already satisfied: packaging>=20.0 in c:\users\for\miniconda3\lib\site-packages (from matplotlib>=2.2->seaborn) (21.3) Requirement already satisfied: pytz>=2020.1 in c:\users\for\miniconda3\lib\site-packages (from pandas>=0.23->seaborn) (2022.1) Requirement already satisfied: six>=1.5 in c:\users\for\miniconda3\lib\site-packages (from python-dateutil>=2.7->matplotlib>=2.2->seaborn) (1.15.0) Installing collected packages: scipy, seaborn Successfully installed scipy-1.8.0 seaborn-0.11.2 Note: you may need to restart the kernel to use updated packages.
import seaborn as sns
titanic = sns.load_dataset('titanic')
df = titanic.loc[:, ['age', 'fare']]
print(df.head())
print(type(df))
age fare 0 22.0 7.2500 1 38.0 71.2833 2 26.0 7.9250 3 35.0 53.1000 4 35.0 8.0500 <class 'pandas.core.frame.DataFrame'>
addition = df + 10
print(addition.head())
print(type(addition))
age fare 0 32.0 17.2500 1 48.0 81.2833 2 36.0 17.9250 3 45.0 63.1000 4 45.0 18.0500 <class 'pandas.core.frame.DataFrame'>
titanic = sns.load_dataset('titanic')
df = titanic.loc[:, ['age', 'fare']]
print(df.tail())
print(type(df))
age fare 886 27.0 13.00 887 19.0 30.00 888 NaN 23.45 889 26.0 30.00 890 32.0 7.75 <class 'pandas.core.frame.DataFrame'>
addition = df + 10
print(addition.tail())
print(type(addition))
age fare 886 37.0 23.00 887 29.0 40.00 888 NaN 33.45 889 36.0 40.00 890 42.0 17.75 <class 'pandas.core.frame.DataFrame'>
subtraction = addition - df
print(subtraction.tail())
print(type(subtraction))
age fare 886 10.0 10.0 887 10.0 10.0 888 NaN 10.0 889 10.0 10.0 890 10.0 10.0 <class 'pandas.core.frame.DataFrame'>
| 파이썬, matplotlib 한글 깨짐 해결 (0) | 2022.05.23 |
|---|---|
| 판다스 기초) 외부 파일 읽어오기, 원하는 파일형식으로 저장하기 (0) | 2022.05.12 |
- DarkNamer 프로그램으로 웬만한 파일 이름은 쉽게 변경이 가능
- ex) 100-1.txt -> 100.txt 으로 변경
for i in range(1,100):
data_file = Path(f"E:\\{i}-1.txt")
data_file.rename(f"E:\\{i}.txt")
| 이미지 용량 줄이기 (0) | 2022.04.19 |
|---|---|
| 폴더에서 원하는 확장자 파일 삭제 (0) | 2021.12.24 |
| 원하는 폴더들 띄우기 (0) | 2021.12.24 |
| 알집폴더 풀기 (0) | 2021.12.24 |
| OpenCV) 이미지 이동 (0) | 2021.11.29 |
import os
from PIL import Image
path = 'E:\\폴더\\' # 원본 폴더
resultPath = 'E:\\폴더' # 결과 폴더(새로 저장할)
# if not os.path.exists(resultPath):
# os.mkdir(resultPath)
list = os.listdir(path)
list.sort()
for filename in list:
file = path + filename
img = Image.open(file)
img.save(os.path.join(resultPath, filename), 'JPEG', qualty=50) # 품질 55로 줄이면서 용량 ↓| 파이썬(python) - 파일 이름 변경 (0) | 2022.05.03 |
|---|---|
| 폴더에서 원하는 확장자 파일 삭제 (0) | 2021.12.24 |
| 원하는 폴더들 띄우기 (0) | 2021.12.24 |
| 알집폴더 풀기 (0) | 2021.12.24 |
| OpenCV) 이미지 이동 (0) | 2021.11.29 |