1. 필답형1 (30%)
: 당일 벼락치기로 중요해보이는 이론만 보고 갔습니다. (12/30)
1. Json
2. 최소제곱법
3. 박스콕스
4. 차원축소
5. 자기조직화지도 SOM
6. 정규성
7. SVM
8. 드롭아웃
9. 스쿱
10. 0.686 -> f1-score 계산
저는 1,4,7,8번 맞았고 지극히 주관적인 의견이지만 작업형1,2에 올인하고 하루 전에 필답형 기출&예상문제 보고 외우시는 것을 추천합니다.
2. 작업형1 (30%)
- 홈페이지에서 응시환경 체험하기를 해보면

이렇게 체험을 할 수 있는데 실제 시험환경과 동일합니다.
파일을 불러오는 a까지 나와있기 때문에 그 이후로 진행하면 됩니다.
1.
1) 1사분위수와 3사분위수 구하기
2) 차이를 절대값으로 표현
3) 소수점 버림
4) 정수형으로 표현 -> 최종 닶은 정수형으로 표현된 값
Q1 = df['컬럼명'].quantile(0.25)
Q3 = df['컬럼명'].quantile(0.75)
sub = np.abs(Q3 - Q1)
i = np.trunc(sub)
a = int(i)답: 36
2. 대충 문제가.. 전체 수(all) 중에서 a와 b가 차지하는 비율을 구하고
그 비율이 0.4~0.5 사이에 존재하고 종류가 video인 개수를 묻는 문제였습니다.
1. ratio가 0.5보다 작고 0.4보다 큰
2. video
답:90
변수명이 기억이 잘 안나서 전체 수 -> all, 종류1-> a, 종류2-> b 로 표현해보자면
# ratio 컬럼을 만듦
df['ratio'] = (df[a] + df[b]) / df['all']
# 비율이 0.4~0.5 사이의 값들
ratio = df[(df['ratio'] > 0.4) & (df['ratio'] < 0.5)]
# 그 중 종류가 비디오인 것의 개수
print(len(ratio['컬럼명'] == 'video'))
3. 2018년 1월에 제작한 영화? 중에서 United Kingdom 단독제작인 영화 개수
- 조건1) 2018년 1월에 제작한 영화
- 조건2) United Kingdom 단독제작 / 컬럼명: country
:Date 컬럼이 September, 6, 2018 이렇게 되어있었습니다.
a['date_added'] = pd.to_datetime(a['date_added'])
a['year'] = a['date_added'].dt.year
a['month'] = a['date_added'].dt.month
cond1 = a['year'] == 2018
cond2 = a['month'] == 1
cond3 = a['country'] == 'United Kingdom'
print(len(a[cond1 & cond2 & cond3]))답: 6
추가로
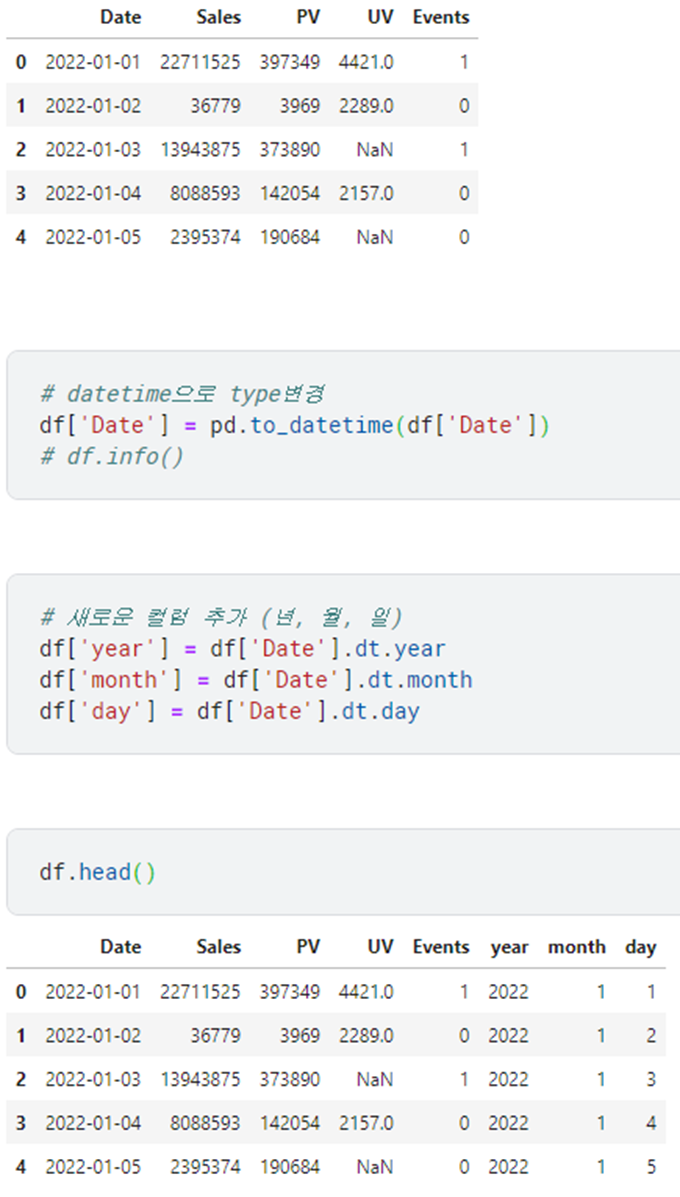
이런 식으로 비슷한 예제로 날짜를 분리하여 조건에 맞는 값을 추출하는 연습을 하면 좋을 것 같습니다.
2. 작업형2
- 사실 제일 막막했는데
[무료] 빅데이터 분석기사 시험 실기(Python) - 인프런 | 강의
국가기술자격증 빅데이터분석기사 실기 with Python 강의입니다. 여러분들의 합격을 응원합니다!, - 강의 소개 | 인프런...
www.inflearn.com
이 분 강의를 듣고 똑같은 유형이 나와서 꾸역꾸역 적었습니다.
무료라서 한번 듣는 것을 추천합니다.
강의 목차 중에서 작업형2 7,8강이 시험문제과 유형이 같았습니다.
(시험에선 결측치가 없었고, 저는 전처리과정은 라벨링, age컬럼만 정규화했습니다..)

응시환경 체험하기처럼 나오는데 이번 시험에서는 y_train이 없었습니다.
X_train의 'segmentation'을 예측하는 문제였습니다.
(X_test에는 segmentation이 없음)
- 전처리: 결측치 없어서 제거안함/ 라벨링/ age만 정규화(나머지 컬럼들은 0 or 1 위주여서..)
- 모델: RandomForestClassifier / AdaBoostClassifier/ VotingClassifier
(모델링은 강의 내용과 동일하게 했습니다.)
시험은 6월 25일에 쳤고
시험결과는 7월 8일에 공개됐습니다.
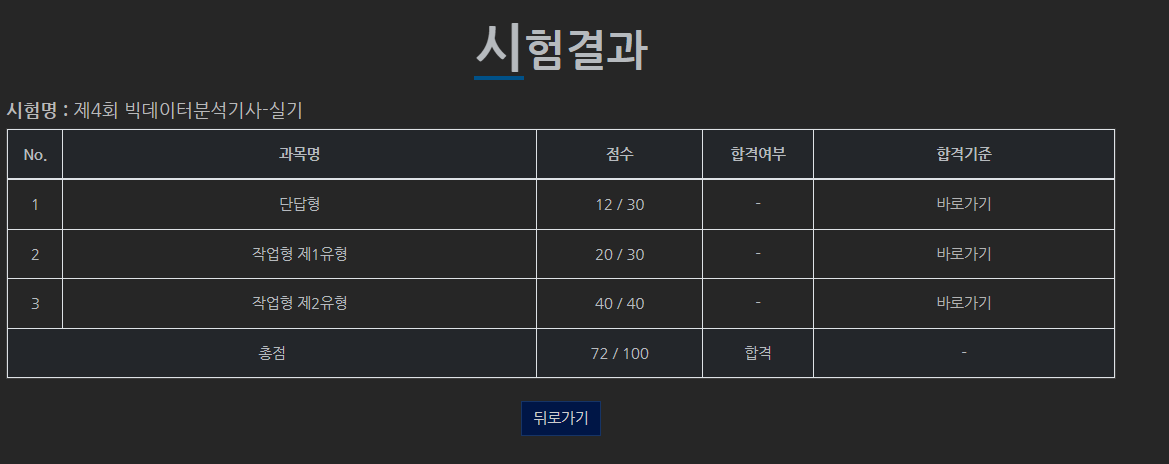
후기 끝.